Introduction
Most aspects of the computer world, especially programming languages, evolve based on need and current trends. Programming languages that are not based on strong foundations will almost certainly fail or they will change often due to very rapid technological changes and trends. T-SQL is one of the long-haul programming languages that has stood the test of time. Mainly because it has strong foundations – mathematics. You certainly don’t need to be a mathematician to write good SQL code (although it does help), but if you understand the key principles of SQL foundations, the better you will understand the SQL language. Without understanding these foundation principles, you can still write T-SQL code, but not quite as efficiently or effectively.
Evolution of T-SQL
As mentioned in the introduction section above, T-SQL is based on a mathematical foundation. Learning just a few of the key principles will help you understand programming in T-SQL. At that point, you will be able to code in T-SQL rather than writing T-SQL in a procedural method. Yes, there is a difference. Later, as you progress as a DBA, you will start to see the difference more clearly. The image below outlines the building blocks of T-SQL.
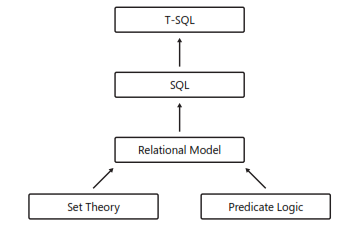
T-SQL is the primary language used to manipulate and manage data in Microsoft’s relational database management system (RDBMS), whether that’s on premises or in the cloud (Microsoft Windows Azure SQL Database). T-SQL is referred to as a dialect of standard SQL. SQL is a standard registered on both the International Organization for Standards (ISO) and the American National Standards Institute (ANSI). Both standards for SQL are basically the same. However, the SQL standard continues to evolve over time as new trends and needs progress.
History of T-SQL
Below you will find a chronological list of T-SQL standards (as of this publication)
| Release Name | Release Date |
|---|---|
| SQL Server 1.0 | 1989 |
| SQL Server 4.2 for NT | 1993 |
| SQL Server 6.0 | 1995 |
| SQL Server 6.5 | 1996 |
| SQL Server 7.0 | 1998 |
| SQL Server 2000 | 2000 |
| SQL Server 2005 | 2006 |
| SQL Server 2008 | 2008 |
| SQL Server 2008 R2 | 2010 |
| SQL Server 2012 | 2012 |
| SQL Server 2014 | 2014 |
| SQL Server 2016 | 2016 |
| SQL Server 2017 | 2017 |
| SQL Server 2019 | 2019 |
| SQL Server 2022 | 2022 |
| SQL Server 2025 | 2025 |
When writing SQL queries, you may encounter both SQL standard syntax and T-SQL–specific variations for the same operation. Although you are working in the T-SQL dialect, certain commands offer two valid forms—one defined by the SQL standard and another provided as a T-SQL extension. A common example is the “not equal to” operator: T-SQL supports !=, while the ANSI SQL standard uses <>. When possible, it is best practice to use the SQL standard syntax, as it improves portability and compatibility across different database platforms unless a vendor-specific feature provides a clear and necessary advantage.
Set Theory
So, what is a set within a set theory? This was best described by Georg Cantor in his article “Algebraic Numbers” that was first published in 1874.
“By a “set” we mean any collection M into a whole of definite, distinct objects m (which are called the “elements” of M) of our perception or of our thought.”
--- Georg Cantor, in “Georg Cantor by Joseph W. Dauben (Princeton University Press, 1990)
You can read the full "English Translation" of Georg Cantor's Set Theory here: Set Theory
Set theory is a fundamental concept in the world of databases and plays a crucial role in the functioning of a relational database management system (RDBMS). It provides the foundation for organizing and manipulating data within tables.In simple terms, set theory deals with collections of objects or elements. In the context of RDBMS, these objects are represented as rows in tables. Sets can be combined using operations such as union, intersection, and difference to perform various data operations.
One key aspect of set theory is that it allows for efficient retrieval and manipulation of data. By representing data as sets, RDBMS can quickly search for specific information based on certain conditions or criteria.
Additionally, set theory enables consistency and integrity within the database by enforcing constraints such as unique values or referential integrity between related tables.
Understanding set theory is essential for anyone working with relational databases. It forms the basis for designing efficient database structures and performing complex queries to extract meaningful insights from vast amounts of data stored in an RDBMS. So next time you work with an RDBMS, remember that behind its functionality lies the power of set theory!
Predicate Logic
Predicate Logic is a foundational concept in Relational Database Management Systems (RDBMS). At its core, Predicate Logic uses logical statements—known as predicates—to define and evaluate relationships between data entities within a relational database.
In RDBMS, Predicate Logic helps define the conditions that must be met for data retrieval and manipulation. These conditions are expressed through various operators such as equality, inequality, greater than, less than, and so on. By using predicate logic in queries and commands, users can specify precisely what data they want to retrieve or modify from the database.
One important aspect of Predicate Logic is that it allows for complex expressions by combining multiple predicates with logical operators like AND and OR. This flexibility enables users to create sophisticated queries that can extract specific information based on various criteria.'
For example, let's say we have a relational database containing information about employees. Using Predicate Logic, we can construct a query to retrieve all employees who have a salary greater than $50,000 and work in the sales department. The query would combine two predicates - one for salary comparison and another for department identification - using an AND operator.
Understanding Predicate Logic is crucial when working with RDBMS because it provides the foundation for expressing precise conditions and extracting relevant data from databases efficiently. It empowers users to make complex queries while ensuring accuracy in retrieving desired results without unnecessary clutter.
Further reading:
Predicate logic in the context that SQL uses it comes from first‑order predicate calculus, developed in modern form by Gottlob Frege and later refined by logicians such as Peano, Russell, and others; SQL itself inherits predicate logic through Edgar F. Codd’s relational model, which is explicitly “based on an applied predicate calculus.” There is no single “SQL predicate logic inventor”; instead, Codd applied existing first‑order predicate logic to data management and query languages, and SQL is one of the industrial realizations of that work. Read or download a copy of the full PDF here: Predicate Logic
Wrap Up
Now that we have the basics of predicate logic and set theory somewhat understood, let's move onto the next article - "Step 5 SQL Server Data Types".
Data types are a fundamental building block of any relational database system and must be clearly understood before designing effective database objects. A solid grasp of data types is essential for creating well-structured tables, views, and other database components, as they directly impact data integrity, performance, storage efficiency, and query accuracy.
